Yazan : Şadi Evren ŞEKER
Bu yazının amacı, özellikle derleyici tasarımı konusunda geçen LR(0) parçalama algoritmasını (parsing algorithm) açıklamaktır. Algoritmanın ismi, iki harften L ve R harflerinden gelmektedir. İlk L harfi, Left to Right parsing (soldan sağa parçalamalı) anlamında, ikinci R harfi ise Rightmost derivation (sağdan azaltmalı) anlamındadır. Algoritmanın isminde bulunan 0 sayısı ise look ahead (ileri bakma sayısının) 0 olduğunu gösterir. Yani parçalama algoritmamız, sadece o andaki terim (harf) ile ilgilenmekte ve daha sonra gelecek olan terimlere bakmamaktadır.
Algoritma, basit bir DFA çizimi ile başlar ve dilin tanımında (genellikle CFG şeklinde verilir) bulunan durumlar bu sonlu otomat (finite automaton) üzerinde gösterilir. Ardından alınan bir girdi (input) için bu otomat üzerinde işlem yapılarak girdi parçalanmaya çalışılır.
Bu yazının içeriğinde algoritma incelenirken yukarıda bahsedildiği üzere iki adımda incelenecektir. İlk adımda DFA çizimini ve aşamalarını göreceğiz, ikinci adımda ise örnek bir girdi için algoritmanın DFA üzerinde nasıl çalıştığını göreceğiz.
Yazının sonunda ise LR(0) algoritmasının sınırlarını anlatacak ve parçalayamayacağı bazı özel dilleri ve neden parçalayamadığını açıklayacağız.
Örnek1 :
Örnek olarak aşağıdaki grameri ele alalım.
S -> A$
A -> aAa
A -> c
Bu gramer için öncelikle bir DFA oluşturarak işe başlayalım. Başlangıç durumunda (starting state) yukarıdaki dilin S durumu ele alınmalıdır:

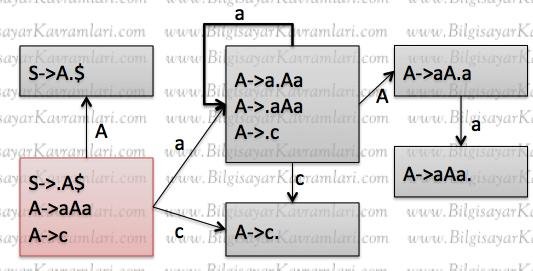
Yukarıdaki şekilde, ilk önce S->A$ ifadesi yerleştiriliyor (şeklin sol alt köşesinde). Bu ifade yerleştirildiğinde bir nokta (.) sembolü, o ana kadar parçalanmış (işlenmiş, parse) kısmı tutmak üzere yerleştiriliyor. Buna göre S->.A$ ifadesi, henüz hiçbir terimin işlenmediğini ve sıradaki işlemenin A terimi olduğunu ifade ediyor.
Bu durum aslında özel bir durumdur, yani sıradaki terim bir devamlı (non-terminal) ifadedir ve bu ifadeler büyük harfle gösterilir ve girdide (input) yer almaz ve gramerde daha karmaşık bir ifadeye dönüşüm için kullanılır (bkz. CFG konusu). Bu durumda, yani bir devamlının (non-terminal) sırada olduğu durumlarda bu devamlı da, gramerdeki tanımı itibariyle açılır ve o andaki duruma eklenir. İçinde bulunduğumuz duruma, A devamlısının (non-terminal) açılımı olan kuralları da bu yüzden ekliyoruz.
Sırada gelebilecek ifadelerin işlenmesi var. Şu anda beklediğimiz ve gelebilecek semboller {A,a,c} kümesindeki sembollerdir. Her sembol için farklı bir yol çiziyor ve yeni birer durum işaretliyoruz:

Yukarıdaki yeni haliyle, DFA çizimimiz 3 farklı yola gidebilmektedir. Bunlardan A gelmesi durumu basit bir durumdur ve bu durum shift (kaydırma) olarak değerlendirilir. Dikkat edilirse burada noktanın konumu ilerletilmiştir ve sıradaki terim $ olarak bulunduğu için ($ girdinin sonu, end of input anlamındadır) makine kabul durumu olarak biter. Diğer durumlar ise henüz doldurmadığımız durumlardır ve bu durumları sırasıyla inceleyelim.

Öncelikle “a” gelmesi durumuna bakalım. Bu durumda gramer tarınımımızda bulunan ve a terimini bekleyen tek kural olan A->.aAa kuralındaki nokta ilerletiliyor ve A->a.Aa kuralı olarak yazılıyor. Ancak yine bir devamlı (non-terminal) olan A terimi ile karşılaşıyoruz. Bu durumda, daha önce yaptığımız gibi bu devanlının (non-terminal) açılımını da durumun içerisine yazıyoruz.
Diğer bir ihtimal ise A->.c beklentisini tatmin ederek A->c. Şeklindeki kaydırma (shift) işlemidir. Bu durum da yukarıdaki şekidle gösterilmiştir (sağ alt köşedeki durum). Bu gösterilen durum aslında özel bir durumdur ve buna ikame (reduce) durumu denir. Yani A->c şeklindeki açılım aslında c olan yere A yazılabileceği anlamını taşır ki bunu örnek bir girdinin parçalanması sırasında daha net anlayacağız.
Sırada diğer beklentiler var. Sağ üst köşede duran durumdaki beklentilerimiz {A,a,c} kümesindeki ifadelerdir ve bunların açılımlarını aşağıdaki şekilde gösterebiliriz:

Yukarıdaki yeni haliyle DFA çizimimizde gelebilecek 3 durum açılmış ve sadece A->aA.a ile gösterilen ve A gelmesi durumunu ifade eden ihtimal için yeni bir durum eklenmiştir. Diğer ihtimaller için mevcut durumlar kullanılmıştır. Burada a gelme ihtimali dikkate alınmalıdır. Buna göre a geldiğinde yine aynı durumda olacağız ancak bu durumun altında yeni bir durum açılacaktır. Bunu parçalama anında göstereceğiz.
Gelelim son açılmamış durum olan ve bir önceki adımda yeni eklenen sağ üst köşedeki duruma:

Yeni haliyle DFA çizimimizde, son ihtimalin beklentisi olan a terimi geldiğinde yine bir ikame(reduce) durumu eklenmiştir.
Artık DFA çizimimizi bitirdik. Bir sonraki aşama olan bir girdinin parçalanmasını adım adım inceleyebiliriz. Örnek olarak “aacaa” girdisini parçalamak istiyor olalım.
Öncelikle bu girdinin parçalanması sırasında yaşanacak bir problemi göstermek istiyorum. Ardından bu problemin çözümü için DFA üzerinde ufak bir hile yapacağız.
Girdimiz aacaa olduğuna göre başlangıç durumunda parçalama işlemine başlıyoruz.
Başlangıç durumundayken, gelen ilk terim olan “a” için gideceğimiz durum DFA üzerinde açıkça tanımlanmış. Bu yola devam ediyoruz ve girdimizden “ a” terimini işlediğimiz için siliyoruz. Yeni durumda girdimiz “abaa”t şeklinde düşünülebilir:

Sıradaki terim yine bir “a” sembolü. Yapacağımız işlem aynı durumda kalmak. Ve girdiyi “baa” şekline indirgemek. Ancak gel gelelim bu durumda kaç kere durduğumuzu kaybediyoruz. Yani “aba” girdisi, “aabaa” girdisi veya “aaabaaa” girdilerinin tamamı için bu durumda kalacağız ve bu gerçek bizim parçalama işlemimizi zora sokuyor. Bunun çözümü için durumlara birer sayı ataması yapmak akıllıca bir yöntemdir.

Yukarıdaki şekilde, her durumda (state) bir numara bulunmaktadır. Artık takip işlemi yapılabilir. Nasıl yaptığımızı baştan itibaren görelim. Yine “aacaa” girdisi için başlangıç durumundan başlıyoruz:

ilk terim için devam yolu olan “a” yolunu seçip 3. duruma geçiyoruz ve şimdiye kadar geçtiğimiz düğümleri bir listede tutuyoruz:

Yeni halinde girdimiz “13.acaa” şeklini almıştır. Devam edelim, sıradaki girdimiz bir “a” terimi. O halde, yine aynı durumda kalacağız ancak girdimiz “133.caa” şeklini alacak. Dikkat ederseniz artık kaç kere 3. durumda kaldığımızı sayabiliyoruz.
Devam edelim ve sıradaki terim olan “ c” için DFA‘i işletelim:

Son haliyle girdimizi “1334.aa” şekline getirebiliriz. Ancak burada dikat edilecek bir husus, bir ikame (reduce) durumuna erişmiş olmamız. Bunun anlamı, girdimizde bulunan “c” terimi yerine A terimini yazabilecek olmamız. O halde aslında “133.Aaa” şeklinde girdimizi düşünebiliriz. Bu ikame (reduce) bizi bir önceki durum olan 3. duruma geri döndürdü:

Devam edelim ve son kaldığımız 3. durumdan A girdisini işleyelim:

Girdimizin yeni hali, “1335.aa” şeklini almıştır. Devam edip sıradaki a harfini işleyelim:

Son haliyle, 6. duruma ulaştık ve dikkat edilirse bu durumda bir ikame (reduce) işlemidir ve bizi A->aAa tanımının yerine A yazmaya zorlamaktadır. Bunun anlamı, “ 1335.aa” olan girdimizin önce “13346.a” olması ardından da 346 kısmı yerine A yazacağımızdır (3 sayısının a için 5 sayısının A için ve 6 sayısının a için geldiğini düşünebilirsiniz)
O halde “13.Aa” girdisine dönüşüyoruz ve sıradaki terim için yine 3. durumdan devam ediyoruz.

Benzer şekilde 5. duruma geçiş yapıyoruz:

Ve yine bir önceki seferde olduğu gibi 6. duruma devam ediyoruz:

Neticede girdimiz yine aynı “1346” şekline geliyor. Burada yine bir önceki seferde olduğu gibi 346 yerine A koyabiliriz. Ve girdimiz “1A” şekline dönüşür.
Gelelim 1. adıma ve A gelmesi durumuna:

Bu şart, bizi 2. duruma yönlendiriyor ve 2. durumda da girdiyi kabul ediyoruz. Yani bu gramer “aacaa” girdisini kabul etmektedir diyebiliriz.
Farklı bir örnek olarak kabul edilmeyen bir girdiyi inceleyelim:
“aaca” olarak bir girdi verilmiş olsaydı, yukarıdaki gibi girdimiz “13.A” olana kadar aynı adımlarla gidecektik. Ancak 3. durumdan sonra A girdisi için devam ettiğimiz 5. durum ve ardından girdide başka bir terim kalmamasından dolayı 5. durumda çakılmamız ve 5. durumun bir kabul durumu olmayışı (tek kabul durumunun 2. durum olduğunu hatırlayın) bizim bu girdiyi kabul etmememiz demek olacaktı.
Gelelim LR(0) algoritmasının yeteneklerinin kısıtlarına. Ne yazık ki LR(0) algoritması, reduce/reduce (ikame/ikame) ve shift /reduce (kaydırma /ikame) çelişkilerine karşı dayanıksızdır. Yani aynı durumda birden fazla ihtimale ikame (reduce) bulunuyorsa veya aynı durumda hem ikame hem kaydırma durumları bulunuyorsa, bu durumda LR(0) algoritmasını kullanamayız.

Örneğin, yukarıdaki kısmi DFA çizimini ele alalım. Burada 6. durumda, iki farklı devamlıdan (non-terminal) birisine geçiş yapılacaktır. Bu devamlı (non-terminal) A da olabilir B de. İşte LR(0) algoritması bu ayırımı yapamadığı için çalışmasında problem olur. Farklı bir durumda shift/reduce (kaydırma/ikame) problemidir. Bunu da aşağıdaki şekilde gösterelim:

Örneğin yukarıdaki haliyle, gelen bir “a” terimi, bir shift (kaydırma) anlamına gelebileceği gibi (yukarıdaki 6. durumun ilk kuralı) bir ikame (reduce) anlamına da gelebilir (yukarıdaki şekildeki 6. durumun ikinci kuralı). Bu problem de bir önceki gibi LR(0) için çözümlenemeyecek bir durumdur ve bu şartları içeren DFA çizilmesi halinde girdiye bakılmaksızın o gramerin LR(0) için uygun olmadığı söylenebilir.
hocam yaptığınız çalışmalar bizler için altın değerinde gerçekten çok teşekkürler lütfen yazmayı bırakmayın saygılar
Hocam emeğinize sağlık, yazılarınız çok faydalı ve anlaşılır oluyor. Ancak örnekte “aacaa “girdisindeki c’yi bazı yerlerde b olarak yazmışsınız. Bu ufak hata bazı arkadaşların kafasını karıştırabilir. Teşekkürler…